An SQL join clause combines records from two or more tables. This operation is very common in data processing and understanding of what happens under the hood is important. There are several common join types:
INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER and CROSS or CARTESIAN.
#============Practical Approach cover all join============
Sample data
All subsequent explanations on join types in this article make use of the following two tables. The rows in these tables serve to illustrate the effect of different types of joins and join-predicates.
Employees table has a nullable column. To express it in terms of statically typed Scala, one needs to use Option type.
val employees = sc.parallelize(Array[(String, Option[Int])](
("Rafferty", Some(31)), ("Jones", Some(33)), ("Heisenberg", Some(33)), ("Robinson", Some(34)), ("Smith", Some(34)), ("Williams", null)
)).toDF("LastName", "DepartmentID")
employees.show()
+----------+------------+
| LastName|DepartmentID|
+----------+------------+
| Rafferty| 31|
| Jones| 33|
|Heisenberg| 33|
| Robinson| 34|
| Smith| 34|
| Williams| null|
+----------+------------+
Department table does not have nullable columns, type specification could be omitted.
val departments = sc.parallelize(Array(
(31, "Sales"), (33, "Engineering"), (34, "Clerical"),
(35, "Marketing")
)).toDF("DepartmentID", "DepartmentName")
departments.show()
+------------+--------------+
|DepartmentID|DepartmentName|
+------------+--------------+
| 31| Sales|
| 33| Engineering|
| 34| Clerical|
| 35| Marketing|
+------------+--------------+
Inner join
Following SQL code
SELECT *
FROM employee
INNER JOIN department
ON employee.DepartmentID = department.DepartmentID;
could be written in Spark as
employees
.join(departments, "DepartmentID")
.show()
+------------+----------+--------------+
|DepartmentID| LastName|DepartmentName|
+------------+----------+--------------+
| 31| Rafferty| Sales|
| 33| Jones| Engineering|
| 33|Heisenberg| Engineering|
| 34| Robinson| Clerical|
| 34| Smith| Clerical|
+------------+----------+--------------+
Beautiful, is not it? Spark automatically removes duplicated “DepartmentID” column, so column names are unique and one does not need to use table prefix to address them.
Left outer join
Left outer join is a very common operation, especially if there are nulls or gaps in a data. Note, that column name should be wrapped into scala
Seq if join type is specified.employees
.join(departments, Seq("DepartmentID"), "left_outer")
.show()
+------------+----------+--------------+
|DepartmentID| LastName|DepartmentName|
+------------+----------+--------------+
| 31| Rafferty| Sales|
| 33| Jones| Engineering|
| 33|Heisenberg| Engineering|
| 34| Robinson| Clerical|
| 34| Smith| Clerical|
| null| Williams| null|
+------------+----------+--------------+
Other join types
Spark allows using following join types:
inner, outer, left_outer, right_outer, leftsemi. The interface is the same as for left outer join in the example above.
For cartesian join column specification should be omitted:
employees
.join(departments)
.show(10)
+----------+------------+------------+--------------+
| LastName|DepartmentID|DepartmentID|DepartmentName|
+----------+------------+------------+--------------+
| Rafferty| 31| 31| Sales|
| Rafferty| 31| 33| Engineering|
| Rafferty| 31| 34| Clerical|
| Rafferty| 31| 35| Marketing|
| Jones| 33| 31| Sales|
| Jones| 33| 33| Engineering|
| Jones| 33| 34| Clerical|
| Jones| 33| 35| Marketing|
|Heisenberg| 33| 31| Sales|
|Heisenberg| 33| 33| Engineering|
+----------+------------+------------+--------------+
only showing top 10 rows
Warning: do not use cartesian join with big tables in production.
Join expression, slowly changing dimensions and non-equi join
Spark allows us to specify join expression instead of a sequence of columns. In general, expression specification is less readable, so why do we need such flexibility? The reason is non-equi join.
One application of it is slowly changing dimensions. Assume there is a table with product prices over time:
val products = sc.parallelize(Array(
("steak", "1990-01-01", "2000-01-01", 150),
("steak", "2000-01-02", "2020-01-01", 180),
("fish", "1990-01-01", "2020-01-01", 100)
)).toDF("name", "startDate", "endDate", "price")
products.show()
+-----+----------+----------+-----+
| name| startDate| endDate|price|
+-----+----------+----------+-----+
|steak|1990-01-01|2000-01-01| 150|
|steak|2000-01-02|2020-01-01| 180|
| fish|1990-01-01|2020-01-01| 100|
+-----+----------+----------+-----+
There are two products only: steak and fish, price of steak has been changed once. Another table consists of product orders by day:
val orders = sc.parallelize(Array(
("1995-01-01", "steak"),
("2000-01-01", "fish"),
("2005-01-01", "steak")
)).toDF("date", "product")
orders.show()
+----------+-------+
| date|product|
+----------+-------+
|1995-01-01| steak|
|2000-01-01| fish|
|2005-01-01| steak|
+----------+-------+
Our goal is to assign an actual price for every record in the orders table. It is not obvious to do using only equality operators, however, spark join expression allows us to achieve the result in an elegant way:
orders
.join(products, $"product" === $"name" && $"date" >= $"startDate" && $"date" <= $"endDate")
.show()
+----------+-------+-----+----------+----------+-----+
| date|product| name| startDate| endDate|price|
+----------+-------+-----+----------+----------+-----+
|2000-01-01| fish| fish|1990-01-01|2020-01-01| 100|
|1995-01-01| steak|steak|1990-01-01|2000-01-01| 150|
|2005-01-01| steak|steak|2000-01-02|2020-01-01| 180|
+----------+-------+-----+----------+----------+-----+
This technique is very useful, yet not that common. It could save a lot of time for those who write as well as for those who read the code.
Inner join using non primary keys
Last part of this article is about joins on non unique columns and common mistakes related to it. Join (intersection) diagrams in the beginning of this article stuck in our heads. Because of visual comparison of sets intersection we assume, that result table after inner join should be smaller, than any of the source tables. This is correct only for joins on unique columns and wrong if columns in both tables are not unique. Consider following DataFrame with duplicated records and its self-join:
val df = sc.parallelize(Array(
(0), (1), (1)
)).toDF("c1")
df.show()
df.join(df, "c1").show()
// Original DataFrame
+---+
| c1|
+---+
| 0|
| 1|
| 1|
+---+
// Self-joined DataFrame
+---+
| c1|
+---+
| 0|
| 1|
| 1|
| 1|
| 1|
+---+
Note, that size of the result DataFrame is bigger than the source size. It could be as big as n2, where n is a size of source.
Joining three or more tables in SQL
There may occur some situations sometimes where data needs to be fetched from three or more tables. This article deals with two approaches to achieve it.
Example:
Creating three tables:
Creating three tables:
- student
- marks
- details
Note: Click on image if not clear to view in bigger size.
Table 1: student
create table student(s_id int primary key,
s_name varchar(20));
insert into student values(1, 'Jack');
insert into student values(2, 'Rithvik');
insert into student values(3, 'Jaspreet');
insert into student values(4, 'Praveen');
insert into student values(5, 'Bisa');
insert into student values(6, 'Suraj');

Table 2: marks
create table marks(school_id int primary key, s_id int,
score int, status varchar(20));
insert into marks values(1004, 1, 23, 'fail');
insert into marks values(1008, 6, 95, 'pass');
insert into marks values(1012, 2, 97, 'pass');
insert into marks values(1016, 7, 67, 'pass');
insert into marks values(1020, 3, 100, 'pass');
insert into marks values(1025, 8, 73, 'pass');
insert into marks values(1030, 4, 88, 'pass');
insert into marks values(1035, 9, 13, 'fail');
insert into marks values(1040, 5, 16, 'fail');
insert into marks values(1050, 10, 53, 'pass');
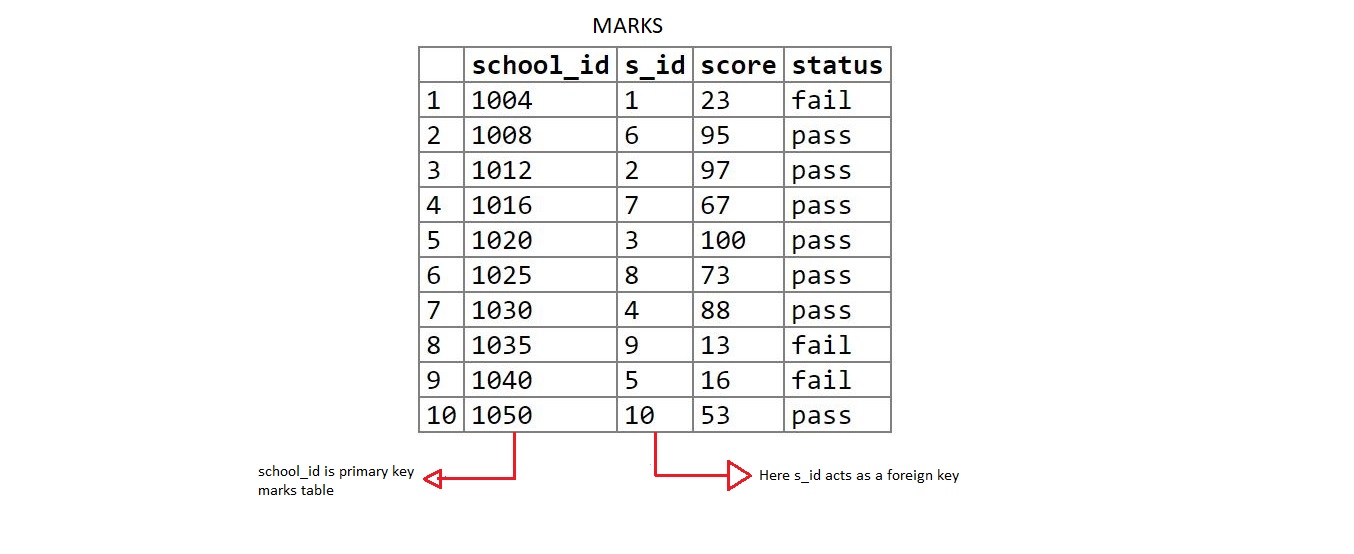
Table 3: details
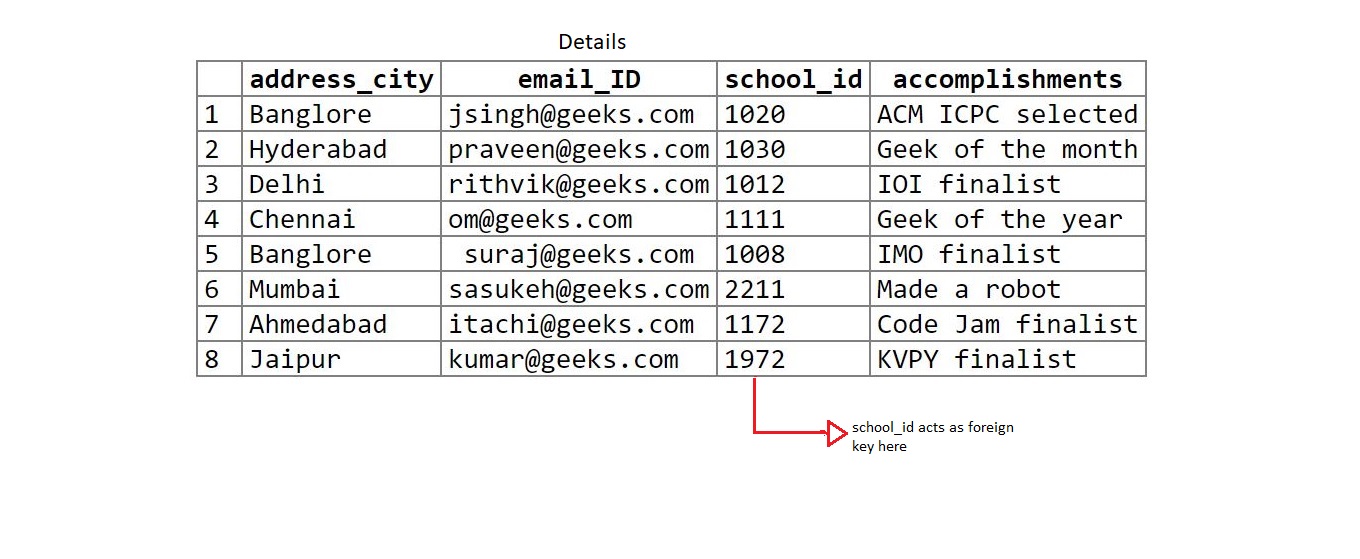
create table details(address_city varchar(20), email_ID varchar(20),
school_id int, accomplishments varchar(50));
insert into details values('Banglore', 'jsingh@geeks.com',
1020, 'ACM ICPC selected');
insert into details values('Hyderabad', 'praveen@geeks.com',
1030, 'Geek of the month');
insert into details values('Delhi', 'rithvik@geeks.com',
1012, 'IOI finalist');
insert into details values('Chennai', 'om@geeks.com',
1111, 'Geek of the year');
insert into details values('Banglore', ' suraj@geeks.com',
1008, 'IMO finalist');
insert into details values('Mumbai', 'sasukeh@geeks.com',
2211, 'Made a robot');
insert into details values('Ahmedabad', 'itachi@geeks.com',
1172, 'Code Jam finalist');
insert into details values('Jaipur', 'kumar@geeks.com',
1972, 'KVPY finalist');
Two approaches to join three or more tables:
1. Using joins in sql to join the table:
The same logic is applied which is done to join 2 tables i.e. minimum number of join statements to join ntables are (n-1).
Query:
1. Using joins in sql to join the table:
The same logic is applied which is done to join 2 tables i.e. minimum number of join statements to join ntables are (n-1).
Query:
select s_name, score, status, address_city, email_id, accomplishments from student s inner join marks m on s.s_id = m.s_id inner join details d on d.school_id = m.school_id;
Output:

2. Using parent-child relationship:
This is rather an interesting approach. Create column X as primary key in one table and as foreign key in another table (i.e creating a parent-child relationship).
Let’s look in the tables created:
s_id is the primary key in student table and is foreign key in marks table. (student (parent) – marks(child)).
school_id is the primary key in marks table and foreign key in details table. (marks(parent) – details(child)).
This is rather an interesting approach. Create column X as primary key in one table and as foreign key in another table (i.e creating a parent-child relationship).
Let’s look in the tables created:
s_id is the primary key in student table and is foreign key in marks table. (student (parent) – marks(child)).
school_id is the primary key in marks table and foreign key in details table. (marks(parent) – details(child)).
Query:
select s_name, score, status, address_city, email_id, accomplishments from student s, marks m, details d where s.s_id = m.s_id and m.school_id = d.school_id;
Output:
Conclusion
This scenario covered different join types implementations with Apache Spark, including join expressions and join on non-unique keys.
Apache Spark allows developers to write the code in the way, which is easier to understand. It improves code quality and maintainability.
No comments:
Post a Comment