Spark -Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing.
Features-
1-inmemory processing
2-fastest
3-scalable
Download data from:
https://www.kaggle.com/shrutimehta/zomato-restaurants-data
Now tell me how many very good rating, good rating avg ... in this way
group those ratings. you can do it using rdd or dataframe
Task on zomato datasets
val RDD1 = sc.textFile("/home/nitin/datasets/zomato.csv")
val rdd2 = RDD1.flatMap(line=>line.split(" "))
.filter(w => (w =="Excellent") ||
(w == "Very good ")||
(w =="good")).groupBy(_.toString)
.map(ws => (ws._Restaurant_id,ws._Rating_text.sum))
rdd2.collect.foreach(println)
spark-shell to start spark .
----------------------------
val - is constant varibale
var - is variable
val a=20
val b=20
a=a+b ->give error as a is a constant variable
val a=20
val b= 30
a=a+b
print(a)
--------------------
val aa="hadoop"
val av="bigdata"
println(s"values are $aa $av")
*s same like %s or %d in c
println("values are %s %s".format(aa,av))
var dd=90
var ss=21.01
println("values are %s %d".format(aa,dd))
var ss=21.01
println("values are %f".format(ss))
println(
--------------classes and objects--
class A
{
def addition(a:int ,b:int)
{
println(a+b)
}
}
object B
{
def main(args:Array[String])
val mm=new A
pintln("enter the value for a")
val a = scala.io.StdIn.readInt();
val b = scala.io.StdIn.readInt();
println(s"sum is $a $b");
mm.addition(a,b);
}
----------------------
class A
{
def addition(a:Int ,b:Int)
{
println(a+b)
}
def substraction(a:Int,b:Int)
{
println("substraction:%d".format(a-b))
}
def multipication(a:Int,b:Int)
{
println(a*b)
}
def devision(a:Int,b:Int)
{
println(a/b)
}
}
object B
{
def main(args: Array[String])
{
val mm=new A
println("enter the value for a")
val a = scala.io.StdIn.readInt();
val b = scala.io.StdIn.readInt();
println(s"sum is $a $b");
mm.addition(a,b);
println(s"sub is $a $b");
mm.substraction(a,b);
println(s"mul is $a $b");
mm.multipication(a,b);
println(s"devision is $a $b");
mm.devision(a,b);
}
}
--------------function in scala-------------
var b= "hadoop bigdata"
b.length()
var b= "$hadoop bigdata"
b.replaceAll("\\$","")
val dd= """Hadoop Pig Sqoop Flume, Hbase:cassandra:::yarn-mongo"""
dd.replace("[,:-]","")
export SPARK_PREFIX=/home/nitin/spark-2.1.0-bin-hadoop2.7
------------ARRAY mutable---------
import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
var fruits = ArrayBuffer[String]()
fruits += "apple"
fruits += "Banana"
fruits += "Orange"
println(fruits)
-----string array------
var fruits = ArrayBuffer[String](3)
fruits(0) = "apple"
fruits(1)= "Banana"
fruits(2) = "Orange"
println(fruits)
---------------
var fruits = new Array[String](3)
fruits(0) = "apple"
fruits(1)= "Banana"
fruits(2) = "Orange"
println(fruits(0))
println(fruits(1))
println(fruits(2))
for(i <- 0 to 2)
{
println (fruits(i))
}
----------conversion--------
val args = Array("hello","world","it's","me")
val string = args.mkString(" ")
val String = args.mkString(".")
-----------File Input---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines())
{
println(line)
}
----------------operations---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
val lines = Source.fromFile(a).getLines.toList
val lines = Source.fromFile(a).getLines.toArray
----------file Input csv (schema lessloading)---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines())
{
val col = line.split(",")
println(col(0),col(1),col(2),col(3))
}
----------file Input csv (schema based loading)---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines().drop(1))
{
---------------------------------------
-----spark context------------
sc is the default context
rdd-- resileance distrubated dataset( data set can be changed during processing)
types -persistant and unpersistant
val a=sc.textFile("/home/nitin/varsion.txt");
a.collect
--parallize rdd---
[ val b= sc.parallelize("/home/nitin/varsion.txt");
or
val b= sc.parallelize("/home/nitin/varsion.txt",10);
here 10 is for 10 number of parallel processing ]
val a=sc.textFile("//home/nitin/varsion.txt");
val b= sc.parallelize(a.collect)
---------------------map and flatmap----
for row operataion is used
val b= a.map(line => line.split(","))
val b =a.map(_.split(","))
val d=c.map(line => line.split(","))
val cg=b.union(d)
Accumulator:
An “add-only” shared variable that tasks can only add values to.
scala> val accum = sc.accumulator(0, "Accumulator Example")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(4, 2, 3)).foreach(x => accum += x)
scala> accum.value
res4: Int = 9
============SCALA==================
Features-
1-inmemory processing
2-fastest
3-scalable
- Speed − Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing number of read/write operations to disk. It stores the intermediate processing data in memory.
- Supports multiple languages − Spark provides built-in APIs in Java, Scala, or Python. Therefore, you can write applications in different languages. Spark comes up with 80 high-level operators for interactive querying.
- Advanced Analytics − Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
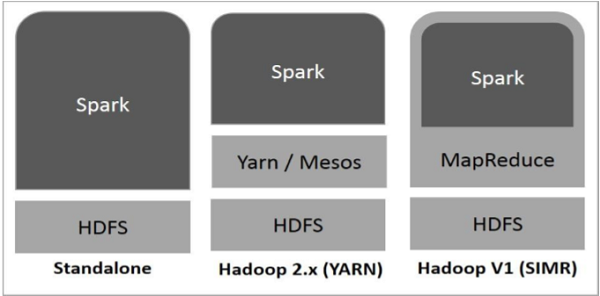
Spark Built on Hadoop
The following diagram shows three ways of how Spark can be built with Hadoop components.
There are three ways of Spark deployment as explained below.
- Standalone − Spark Standalone deployment means Spark occupies the place on top of HDFS(Hadoop Distributed File System) and space is allocated for HDFS, explicitly. Here, Spark and MapReduce will run side by side to cover all spark jobs on cluster.
- Hadoop Yarn − Hadoop Yarn deployment means, simply, spark runs on Yarn without any pre-installation or root access required. It helps to integrate Spark into Hadoop ecosystem or Hadoop stack. It allows other components to run on top of stack.
- Spark in MapReduce (SIMR) − Spark in MapReduce is used to launch spark job in addition to standalone deployment. With SIMR, user can start Spark and uses its shell without any administrative access.
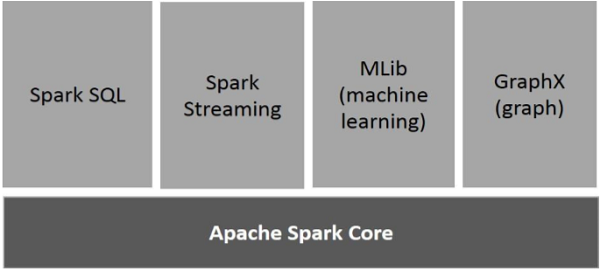
Components of Spark
The following illustration depicts the different components of Spark.
Apache Spark Core
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems.
Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data.
Spark Streaming
Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
MLlib (Machine Learning Library)
MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It is, according to benchmarks, done by the MLlib developers against the Alternating Least Squares (ALS) implementations. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
GraphX
GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
Data structure in spark
1-RDD
2-Dataframe
3-Datasets
Resilient Distributed Datasets
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant collection of elements that can be operated on in parallel.
There are two ways to create RDDs − parallelizingan existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations. Let us first discuss how MapReduce operations take place and why they are not so efficient.
Spark practice -
Install spark and Scala
Open terminal
Type spark-shell
Syntax
Valerie rdd = SC.textFile("path")
https://www.kaggle.com/shrutimehta/zomato-restaurants-data
Now tell me how many very good rating, good rating avg ... in this way
group those ratings. you can do it using rdd or dataframe
Task on zomato datasets
val RDD1 = sc.textFile("/home/nitin/datasets/zomato.csv")
val rdd2 = RDD1.flatMap(line=>line.split(" "))
.filter(w => (w =="Excellent") ||
(w == "Very good ")||
(w =="good")).groupBy(_.toString)
.map(ws => (ws._Restaurant_id,ws._Rating_text.sum))
rdd2.collect.foreach(println)
spark-shell to start spark .
----------------------------
val - is constant varibale
var - is variable
val a=20
val b=20
a=a+b ->give error as a is a constant variable
val a=20
val b= 30
a=a+b
print(a)
--------------------
val aa="hadoop"
val av="bigdata"
println(s"values are $aa $av")
*s same like %s or %d in c
println("values are %s %s".format(aa,av))
var dd=90
var ss=21.01
println("values are %s %d".format(aa,dd))
var ss=21.01
println("values are %f".format(ss))
println(
--------------classes and objects--
class A
{
def addition(a:int ,b:int)
{
println(a+b)
}
}
object B
{
def main(args:Array[String])
val mm=new A
pintln("enter the value for a")
val a = scala.io.StdIn.readInt();
val b = scala.io.StdIn.readInt();
println(s"sum is $a $b");
mm.addition(a,b);
}
----------------------
class A
{
def addition(a:Int ,b:Int)
{
println(a+b)
}
def substraction(a:Int,b:Int)
{
println("substraction:%d".format(a-b))
}
def multipication(a:Int,b:Int)
{
println(a*b)
}
def devision(a:Int,b:Int)
{
println(a/b)
}
}
object B
{
def main(args: Array[String])
{
val mm=new A
println("enter the value for a")
val a = scala.io.StdIn.readInt();
val b = scala.io.StdIn.readInt();
println(s"sum is $a $b");
mm.addition(a,b);
println(s"sub is $a $b");
mm.substraction(a,b);
println(s"mul is $a $b");
mm.multipication(a,b);
println(s"devision is $a $b");
mm.devision(a,b);
}
}
--------------function in scala-------------
var b= "hadoop bigdata"
b.length()
var b= "$hadoop bigdata"
b.replaceAll("\\$","")
val dd= """Hadoop Pig Sqoop Flume, Hbase:cassandra:::yarn-mongo"""
dd.replace("[,:-]","")
export SPARK_PREFIX=/home/nitin/spark-2.1.0-bin-hadoop2.7
------------ARRAY mutable---------
import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
var fruits = ArrayBuffer[String]()
fruits += "apple"
fruits += "Banana"
fruits += "Orange"
println(fruits)
-----string array------
var fruits = ArrayBuffer[String](3)
fruits(0) = "apple"
fruits(1)= "Banana"
fruits(2) = "Orange"
println(fruits)
---------------
var fruits = new Array[String](3)
fruits(0) = "apple"
fruits(1)= "Banana"
fruits(2) = "Orange"
println(fruits(0))
println(fruits(1))
println(fruits(2))
for(i <- 0 to 2)
{
println (fruits(i))
}
----------conversion--------
val args = Array("hello","world","it's","me")
val string = args.mkString(" ")
val String = args.mkString(".")
-----------File Input---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines())
{
println(line)
}
----------------operations---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
val lines = Source.fromFile(a).getLines.toList
val lines = Source.fromFile(a).getLines.toArray
----------file Input csv (schema lessloading)---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines())
{
val col = line.split(",")
println(col(0),col(1),col(2),col(3))
}
----------file Input csv (schema based loading)---------
import scala.io.Source
val a = "/home/nitin/emp.csv"
for (line <- Source.fromFile(a).getLines().drop(1))
{
---------------------------------------
-----spark context------------
sc is the default context
rdd-- resileance distrubated dataset( data set can be changed during processing)
types -persistant and unpersistant
val a=sc.textFile("/home/nitin/varsion.txt");
a.collect
--parallize rdd---
[ val b= sc.parallelize("/home/nitin/varsion.txt");
or
val b= sc.parallelize("/home/nitin/varsion.txt",10);
here 10 is for 10 number of parallel processing ]
val a=sc.textFile("//home/nitin/varsion.txt");
val b= sc.parallelize(a.collect)
---------------------map and flatmap----
for row operataion is used
val b= a.map(line => line.split(","))
val b =a.map(_.split(","))
val d=c.map(line => line.split(","))
val cg=b.union(d)
Accumulator:
An “add-only” shared variable that tasks can only add values to.
scala> val accum = sc.accumulator(0, "Accumulator Example")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(4, 2, 3)).foreach(x => accum += x)
scala> accum.value
res4: Int = 9
============SCALA==================
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WC{
def main(args: Array[String])
{
val conf = new SparkConf().setAppName("WC SCALA").setMaster("local");
val sc = new SparkContext(conf);
val a = sc.textFile("/home/nitin/emp.txt");
val b = a.flatMap(line => line.split(" "))
val c = b.map(word => (word, 1))
val d = c.reduceByKey(_ + _)
d.saveAsTextFile("/home/vaibhav/daata24/")
}
}
==============Apache Spark Tuning ===============
Apache Spark allows developers to run multiple tasks in parallel across machines in a cluster or across multiple cores on a desktop. A partition, aka split, is a logical chunk of a distributed data set. Apache Spark builds Directed Acyclic Graph (DAG) with jobs, stages, and tasks for the submitted application. The number of tasks will be determined based on number of partitions.
import org.apache.spark.SparkConf
object WC{
def main(args: Array[String])
{
val conf = new SparkConf().setAppName("WC SCALA").setMaster("local");
val sc = new SparkContext(conf);
val a = sc.textFile("/home/nitin/emp.txt");
val b = a.flatMap(line => line.split(" "))
val c = b.map(word => (word, 1))
val d = c.reduceByKey(_ + _)
d.saveAsTextFile("/home/vaibhav/daata24/")
}
}
==============Apache Spark Tuning ===============
Apache Spark allows developers to run multiple tasks in parallel across machines in a cluster or across multiple cores on a desktop. A partition, aka split, is a logical chunk of a distributed data set. Apache Spark builds Directed Acyclic Graph (DAG) with jobs, stages, and tasks for the submitted application. The number of tasks will be determined based on number of partitions.
Spark Partition Principles
The general principles to be followed when tuning partition for Spark application is as follows:

Submitting Spark Application in YARN
The Spark submit command with partition tuning, used to execute the RDD and DataFrame API implementation in YARN, is as follows:
1
|
./bin/spark-submit --name FireServiceCallAnalysisRDDStragglerFixTest --master yarn --deploy-mode cluster --executor-memory 2g --executor-cores 2 --num-executors 2 --conf spark.default.parallelism=23 --class com.treselle.fscalls.analysis.SFOFireServiceCallAnalysis /data/SFFireServiceCall/SFFireServiceCallAnalysisPF.jar /user/tsldp/FireServiceCallDataSet/Fire_Department_Calls_for_Service.csv
|
1
|
./bin/spark-submit --name FireServiceCallAnalysisDataFrameStragglerFixTest --master yarn --deploy-mode cluster --executor-memory 2g --executor-cores 2 --num-executors 2 --conf spark.sql.shuffle.partitions=23 --conf spark.default.parallelism=23 --class com.treselle.fscalls.analysis.SFOFireServiceCallAnalysisDF /data/SFFireServiceCall/SFFireServiceCallAnalysisPF.jar /user/tsldp/FireServiceCallDataSet/Fire_Department_Calls_for_Service.csv
|
DataFrame API implementation of application input, shuffles read, and writes is monitored in stages view. The below diagram shows that the input size of shuffle stages is ~17 MB currently and ~849 MB previously. The Shuffle read and write do not have multiple changes.
thanks for tips at SynergisticIT offer the best azure training course in california
ReplyDeleteNice article,keep sharing more posts with us.
ReplyDeleteThnk you..
big data and hadoop training
hadoop admin online course